A imagem fala por si, 4 mil seguidores no Facebook. Desde já agradecemos a todos que partilham o conteúdo da página, comentam, gostam… enfim, todos aqueles que estão a tornar o “MenosFios” numa grande comunidade.
Ainda não nos segue nas redes sociais? Aproveite agora:
A Rockstar está a investigar relatos de vendas iniciais de seu jogo altamente antecipadas. A empresa confirmou a GamesIndustry International, que é no processo de investigação das vendas que eles pretendem determinar como e por que isso está a acontecer.
O problema gira em torno do retalhista online Amazon, que enviou cópias do jogo para os consumidores que fizerem a pré-ordem do título. Imagens de serviços de mídia social têm confirmado o rumor.
Do mesmo modo que a Amazon quebrou a data de lançamento para Grand Theft Auto V, uma loja de jogos em Paris já teria começado a vender cópias do jogo antes do seu lançamento também.
Para dar consistência a esta polêmica surgiu um vídeo no YouTube que mostra uma criança de 11 anos de idade emocionada depois de lhe ser ofertado o jogo GTA V.
Vale lembrar que o GTA V tem uma classificação PEGI 18 no Reino Unido e uma classificação ESRB “Mature” na América do Norte devido ao: Sangue exposto, violência intensa, humor maduro, nudez, palavrões, forte conteúdo sexual, uso de drogas e álcool. Ou seja, o GTA V é um video jogo para maiores de 18 anos em todo o mundo, mesmo para aqueles que não possuem leis especificas de classificação dos jogos como Angola.
Este ocorrido já havia acontecido com o jogo GTA IV. Ao que parece, a Amazon e a loja em Paris quiseram fazer felizes os clientes que fizeram a pré-ordem dando a possibilidade de testarem o jogo em primeira mão quebrando deste modo a data oficial de lançamento especificada pela Rockstar.
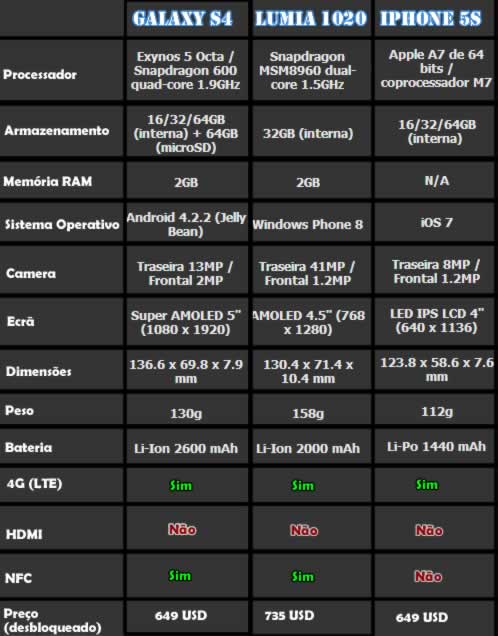
Sempre que a Apple, Samsung ou outra companhia gigante do mundo da tecnologia, decide fazer o lançamento de um novo dispositivo ou serviço, começam as comparações. O grande objectivo é auxiliar os potenciais interessados a escolher o produto certo.
Com o lançamento do iPhone 5S ( o Smartphone topo de gama da Apple), surge a necessidade de verificar as especificações de hardware e software deste smartphone e compara-lo com os últimos lançamentos da concorrência.
Temos mais uma batalha sem igual entre os habituais suspeitos: Samsung e Apple (A Nokia fez um grande trabalho com o Lumia 1020, mas o Windows Phone ainda não entra pra essa batalha. No entanto, menção honrosa…)
A Apple decidiu atacar com o seu processador A7 de 64 bits, o primeiro na história dos smartphones. Mas será que os usuários sabem as vantagens que essa evolução pode trazer?! (noutro artigo falaremos exclusivamente disso).
Há ainda a leitura biométrica, que permitirá que os usuários esqueçam as passwords e usem apenas as impressões digitais.
Será que esses dois factores farão com a Apple domine por completo as outras empresas? A história diz que sim. Depois dos lançamentos da Apple, a venda dos seus dispositivos dispara. A não ser que a concorrência decida investir para evitar que isso aconteça mais uma vez. A Samsung tem tentado e o Galaxy Note 3 está á caminho para entrar pra batalha. Veremos no que isso dá.
Por enquanto, podemos dizer que a balança está equilibrada, até em termos de preços. Quem usa o ecossistema da Apple, provavelmente vai usar o iPhone, e os usuários Android teem tendência de se manter fiéis a plataforma ( a maior parte!)
Para si, qual é o melhor?
Ainda nenhum gamer teve a oportunidade de pôr as suas mãos em cima de nenhuma das consolas que serão lançadas em Novembro, a PS4 e a Xbox One, mas as comparações entre ambas já começam a fazer correr muitas letras nos sites e blogs de tecnologia.
Agora a Edge, um site de vídeo jogos, veio meter mais lenha na fogueira no debate sobre as duas consolas. Segundo eles, a Playstation 4 é a volta de 50% mais rápida que a sua rival da Microsoft, Xbox One. Essa informação foi garantida por vários desenvolvedores que dizem que a diferença na performance das consolas é “significativa” e “óbvia”.
Chegando mais ao detalhe os mesmos dizem que a memória da PS4 lê os dados 40 a 50% mais rapidamente que a Xbox One e as ALU (Unidade de Lógica Aritmética – tradução livre) é também 50% mais rápida.
Num exemplo sem a optimização de nenhuma das consolas e sem usar nenhuma como referencia, a PS4 corre a volta de 30FPS na resolução 1920×1080 e a Xbox One apenas 20 e poucos FPS em 1600×900. Segundo eles a Microsoft sabe disso e parece ter aumentado a velocidade de processamento mas que não “é significativa e não muda muito as coisas”. Alguns gráficos foram mesmo classificados como “horríveis” na Xbox.
Mas como as consolas ainda não estão finalizadas, até Novembro muita coisa ainda pode mudar mas apesar de a Microsoft estar a esforçar-se ao máximo, não parece que dê muito resultado pois as diferenças são muito mais a nível de hardware do que de software.
Acabaram os dias de dependência do seu smartphone para enviar fotos para o Instagram.
A solução chega com esse aplicação compatível com os sistemas Windows e OS X. O nome é Gramblr e pode ser obtido gratuitamente no site: http://gramblr.com/uploader/
Insira o seu nome de utilizador e senha do Instagram
Escolha a foto, ponha a descrição e… pronto, ela será publicada no instagram
Simples e fácil.
Caso a sua foto não esteja a ser aceite, é porque ela não é quadrada (300X300, 250X250… deu pra entender?). Para redimensionar, use o site: http://www.webresizer.com/resizer/ (totalmente grátis).
Mais imagens do aplicativo em acção:
Escolha a foto que quer partilhar no Instagram…
Escreva a descrição da foto…
Links para partilhar nas redes sociais
Resultado final… foto publicada no Instagram com sucesso…
Num dia em que a Apple pensou em dar um passo para superar a concorrência, a concorrência aproveitou um bocado para gozar literalmente com a Apple. Dois dos seus mais directos adversários, a Motorola (Google) e a Nokia (Microsoft), publicaram em seus murais algumas mensagens simpáticas para a Apple.
A Motorola e o iPhone 5S
A empresa americana publicou no seu mural do Twitter a seguinte frase com o objectivo de tentar ridicularizar a Apple:
Traduzindo: “Lembra-se daquela época em que você estava empolgado por dar as suas impressões digitais? Nós também não”. Esta frase poderá ser um tremendo golpe no estômago que a Apple poderá levar. É que nos últimos tempos são tantas as notícias de invasões de dados pessoais que foram surgindo, mais e mais com o caso Snowden, que a Apple pode ter dado, e não por sua culpa mas pelo que aconteceu entre os planos e a produção do iPhone 5S, um tiro no pé sem querer.
Quem perde? A Apple com menos vendas de pessoas desconfiadas em que outros tenham acesso aos seus dados pessoais mais uma vez e desta vez podem ser as suas impressões digitais, e Quem ganha com isso? Claro, a concorrência.
A Nokia e o iPhone 5C
A Nokia aproveitou para atacar a Apple no seu outro modelo lançado no dia 10, o iPhone 5C. A empresa finlandesa apresentou no seu Twitter:
Esta imagem apresenta a sua linha Lumia e goza com a imitação da Apple. A frase foi “a imitação é a melhor forma de elogio” mostrado em imagens e palavras que a Apple inspirou-se nos seus Lumias para os iPhones 5C. De duas uma, podemos encarar essa frase como um sarcástico “obrigado Apple” ou um directo “”#º~ #*@^& Apple”.
Não satisfeita a Nokia também não quis deixar de fora o iPhone 5S e meteu outra imagem no Twitter com a frase “gangsters de verdade não usam celulares dourados”.
A Samsung é que ainda não se manifestou mas de certeza terá algo a dizer sobre este lançamento da Apple, e nós ficaremos a espera para partilhar com vocês. Normalmente a empresa niponica adora “picar” a Apple e os seus “fanboys” com vídeos. Portanto devem estar na fase de gravação ou pós-produção, já já estará a rodar pelo YouTube. A malta espera…
Esta é mais uma daquelas notícias que surge graças a ideias “pouco ortodoxas” de departamentos de marketing. Desta vez é a Microsoft que aparece em grande plano, propondo algo interessante: trocar o seu iPad antigo por 200 USD.
Pois é, numa estratégia diferente para conseguir mais compradores para o seu Tablet, o Surface, a Microsoft ataca o família de tablets com mais sucesso na América, o nosso conhecido iPad. Não importando se é a versão 1, 2, 3 ou 4. Por outro lado, os 200 USD ganhos só poderão ser usados para comprar dispositivos da Microsoft, preferencialmente os seus tablets “Surface”.
Depois de perder 900 milhões com um produto, qualquer coisa vale, até “corromper” os utilizadores da concorrência.
A má notícia é que a promoção será feita apenas nos Estados Unidos e no Canadá. Já começou e dia 27 de Outubro verá o seu fim. Até lá a Microsoft terá lançado o Surface 2, com hardware e software melhorados e, quem sabe, um preço mais acessível, uma vez que esse último item tem sido o calcanhar de Aquiles da Microsoft.
Ao que parece muito poucos gostaram do que a Apple apresentou no dia 10 deste mês. Em mais um evento anual normalmente marcado para o lançamento de novos iPhones, a empresa da maçã mostrou ao mundo o iPhone 5S e 5C. Houve reacções de investidores, concorrentes e clientes.
Investidores
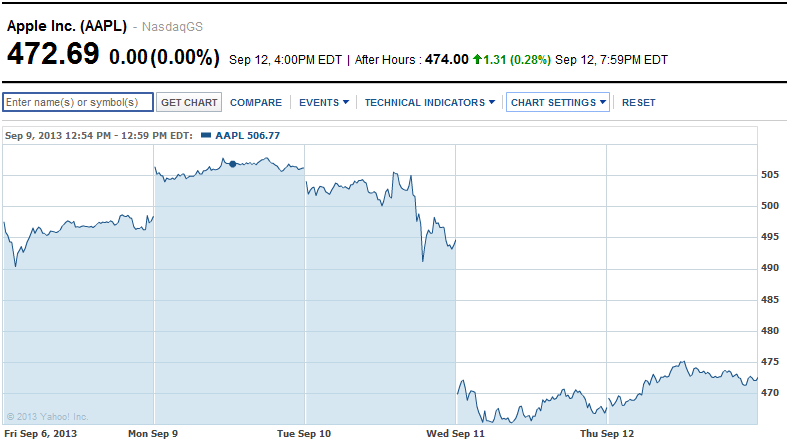
A reacção dos investidores foi bem visível no dia seguinte ao lançamento. A Apple teve uma queda na bolsa e as acções desceram em 5 pontos percentuais, devido as analises financeiras do UBS, JP Morgan, Credit Suisse e o Bank of America.
Fonte: Yahoo Finance
A principal razão, além da falta de inovação nos iPhones, para estas análises pessimistas tem a ver com o iPhone 5C. Supostamente seria o telemóvel capaz de competir com a linha intermédia da Samsung, ou seja, seria o esperado telemóvel mais acessível da Apple, algo que não aconteceu. Tanto que num dos seus principais mercados, o chinês, o 5C que será a linha mais baixa da Apple, ainda será um telemóvel muito caro. Caro o suficiente para continuar a não conseguir competir nesse mercado.
A frase de Mark Moskowitz da JP Morgan pode resumir bastante o que pensam os investidores sobre o lançamento:
“O iPhone 5C de baixo custo pode não ter um preço pequeno o suficiente, algo que em nossa visão pode limitar sua entrada no segmento de smartphones intermédios”.
Quer ver jovens com espirito empreendedor e criativo? Vá ao Centro de Convenções de Talatona e passeie pela 5ª Feira do inventor e criador Angolano.
De 11 a 15 de Setembro, com exposições de criadores de (quase) todo país e alguns expositores convidados de outros pontos do mundo. Os visitantes poderão encontrar livros, esculturas, quadros, máquinas com funcionalidades inovadoras, várias demonstrações laboratoriais ( dadas por várias empresas e instituições de ensino).
Nesse segundo dia, alguns projectos chamaram a nossa atenção:
Máquina de fazer funge! Sim, você leu correctamente…Directamente do Huambo, o fogão com múltiplas funções…funciona com electricidade, gás butano ou qualquer outro gás inflamável…Um dos projectos do Instituto Nacional de Telecomunicações (ITEL), um sistema que alerta os pais, quando uma criança estiver em perigo…
Veja mais imagens da feira:
Na entrada o anúncio, 5ª edição da Feira do Inventor/Criador Angolano
Uma vista geral das stands montadas na feira.
Uma vista geral das stands montadas na feira.
Uma vista geral das stands montadas na feira.
Demonstrações técnicas no Stand da TVCabo Angola
Invenção de António Baxe, a Máquina de fazer funge…
Máquina de fazer funge! Sim, você leu correctamente…
A Multitel também marcou presença…
Estudantes que projectaram o controlador de nível de água
Controlador de nível de água
Stand da TVCabo Angola
Stand da Associação Startup Angola
Stand da Associação Startup Angola
Stand da Associação Startup Angola
Sistema de segurança…
Ar condicionado caseiro de baixo consumo…
Directamente do Huambo, o fogão com múltiplas funções
Directamente do Huambo, o fogão com múltiplas funções
Directamente do Huambo, o fogão com múltiplas funções
Um dos projectos do Instituto Nacional de Telecomunicações (ITEL)
Stand da Universidade Católica, com alguns aplicativos para demonstração…
Várias províncias/instituições representadas nesta feira…
Faltando poucos dias para o lançamento do Grand Theft Auto V, foram publicadas duas petições no Change.org. Uma na esperança de impedir a Rockstar lance a versão PC de GTA V e a outra totalmente a favor do lançamento da versão PC do jogo.
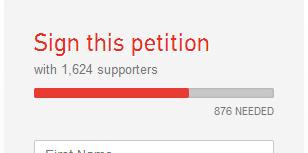
A primeira, criada por Trevor Phillips, visa o não lançamento do jogo para a plataforma PC. O mesmo alega que isto iria servir de lição para que os PC Gamers parassem de roubar jogos. Neste momento apenas aproximadamente 1.624 pessoas apoiaram esta causa. Ela teve fundamento pelo facto de que nenhuma versão para PC fora anunciada pela Rockstar.
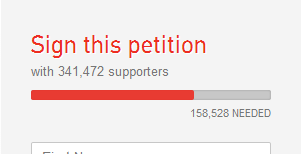
Por outro lado, existe uma petição criada pelo Mike Julliard, incentivando a Rockstar a lançar o seu jogo para a plataforma PC, ela já tem mais de 340 mil apoiantes. Se a decisão dependesse apenas destas petições, seria provável que o GTA V fosse lançado para PC em algum momento no futuro possivelmente ao lado de versões next-gen do jogo.
As duas petições podem ser encontradas aqui: A favor e contra. Vale lembrar que o jogo será lançado no próximo dia 17 de setembro e que o modo online será lançado 2 semanas depois.